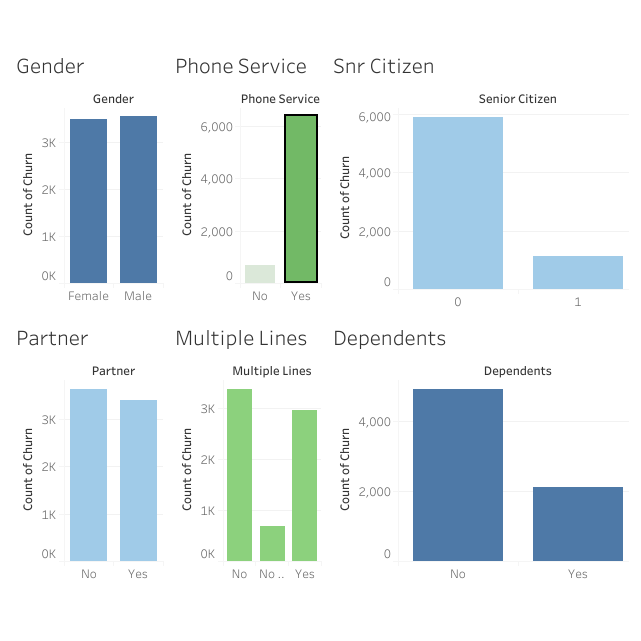
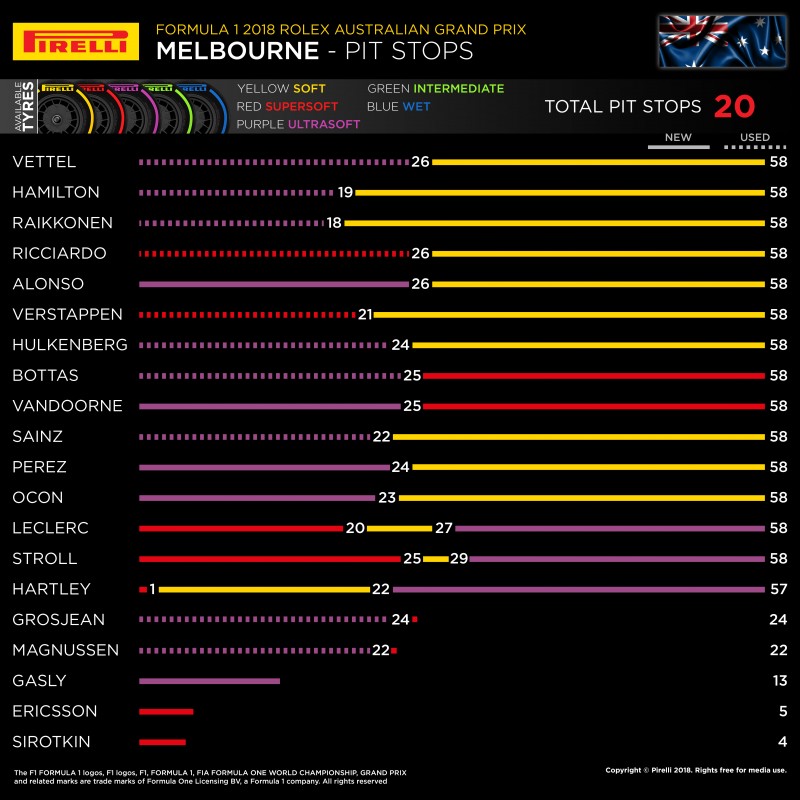
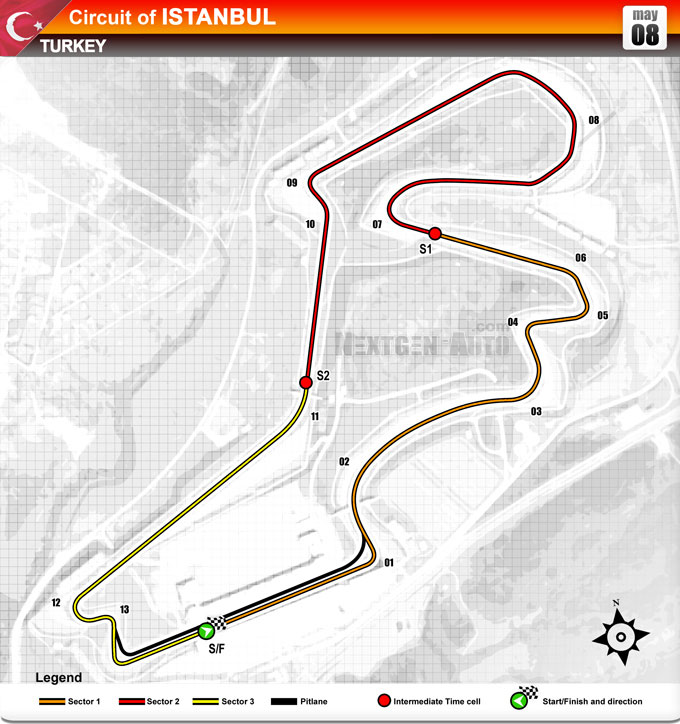
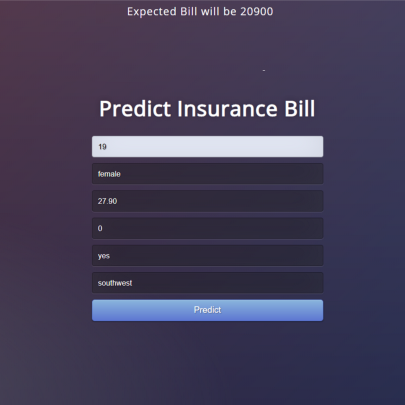
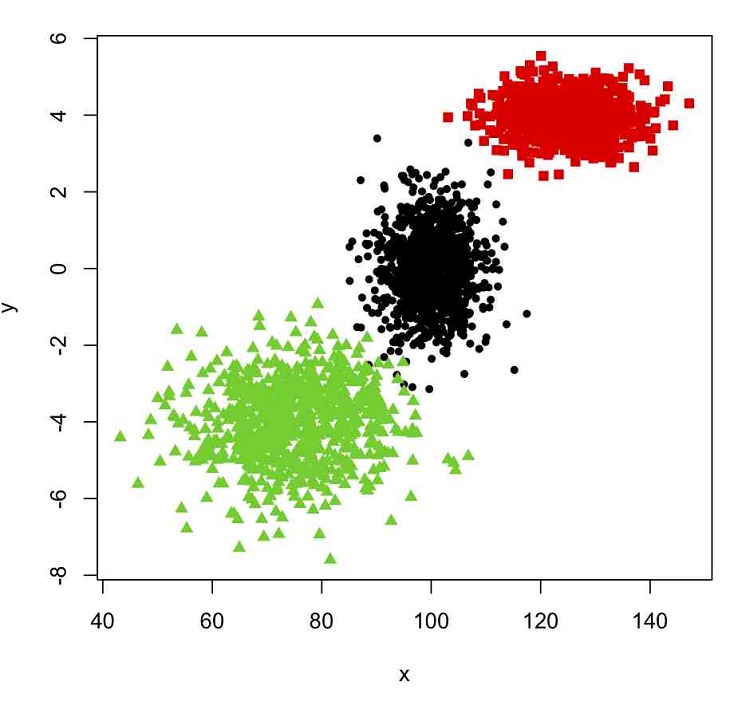
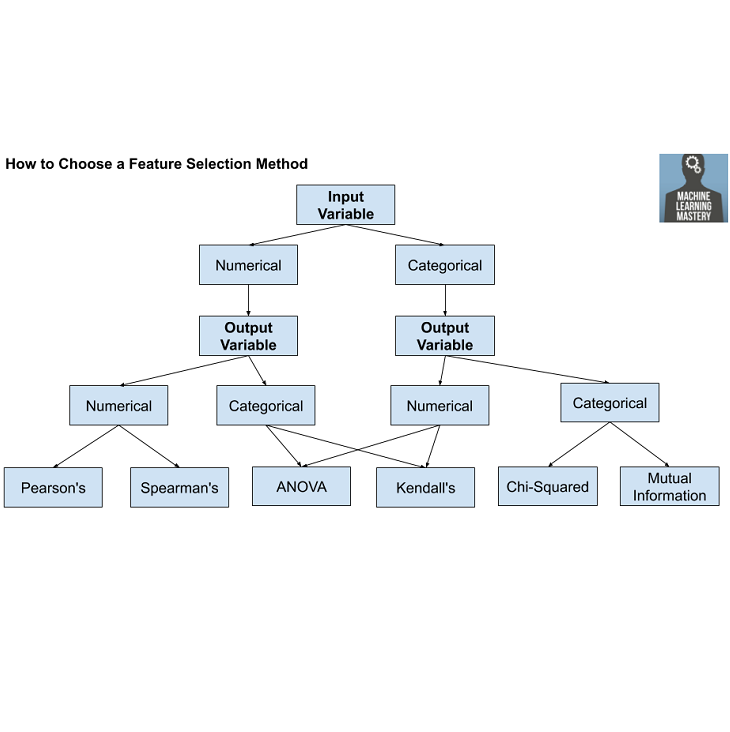
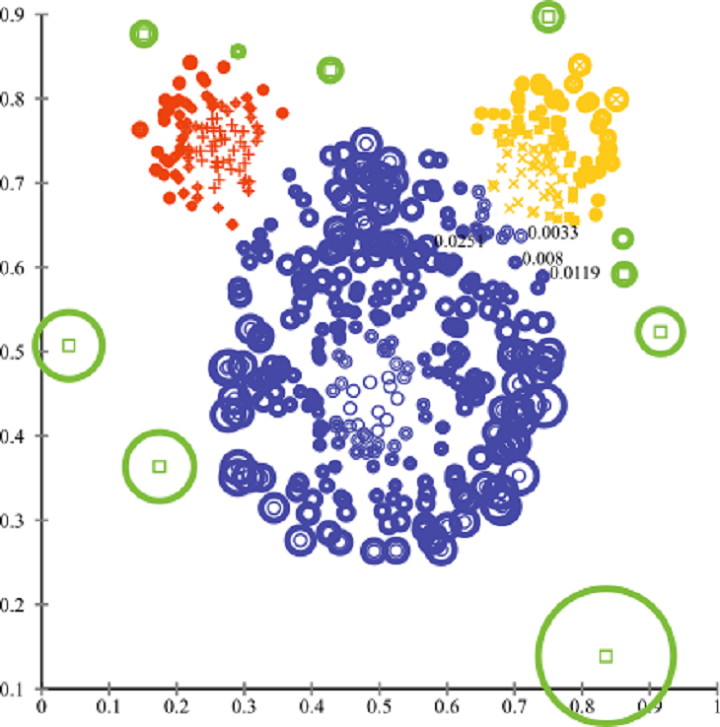
Bio. I am Norbert Eke, an enthusiastic, intellectually curious, data-driven, and solution-oriented Data Scientist with problem-solving strengths and expertise in machine learning & data analysis.
I completed my graduate studies at
Carleton University in Ottawa, Canada and I have been awarded the
Master of Computer Science Specialization in Data Science degree (Class of 2020).
I worked in Canada for a short period of time, then in 2021 I relocated to Zürich, Switzerland, where I currently live and work. I have 2.5 years of work experience in Data Science and Machine Learning.
I am a motivated person with excellent leadership and communication skills. I am a self-starter, proactive, goal-oriented, hands-on learner with a passion for growth within my expertise area, creating meaningful and impactful work using new data science and machine learning techniques.
I always have a positive mindset and I am looking to gain valuable experiences in data science. I find professional fulfillment in innovation, impact and providing a meaningful contribution to society.
I am a big fan of Bayesian statistics, customer lifetime values, classification tasks, cluster analysis, outlier detection, recommendation systems, and data visualization. I enjoy analyzing data and solving real-life problems using data science and machine learning.
During my graduate studies I conducted research in Dr. Olga Baysal’s Software Analytics lab.
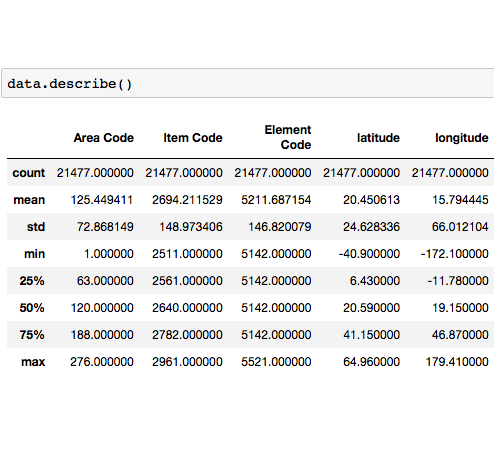
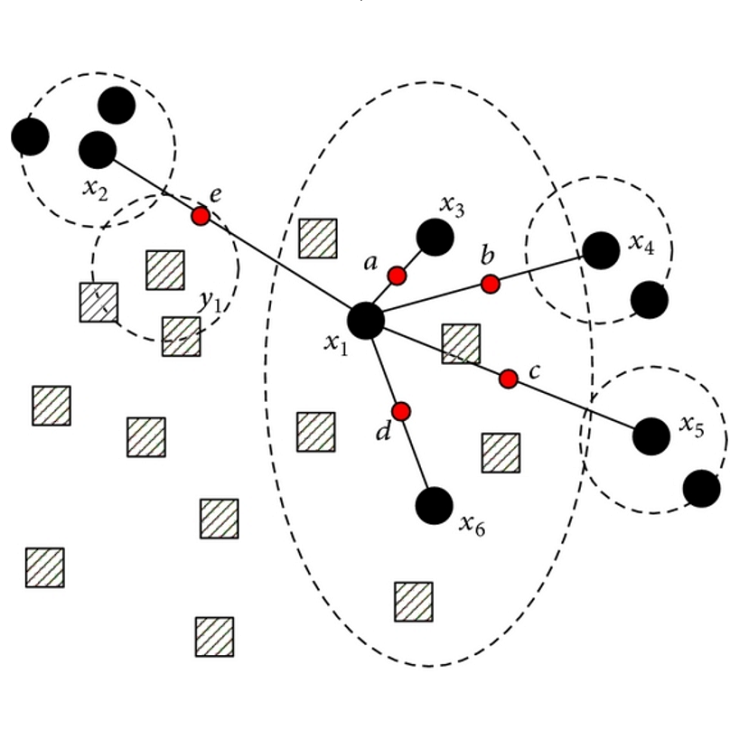
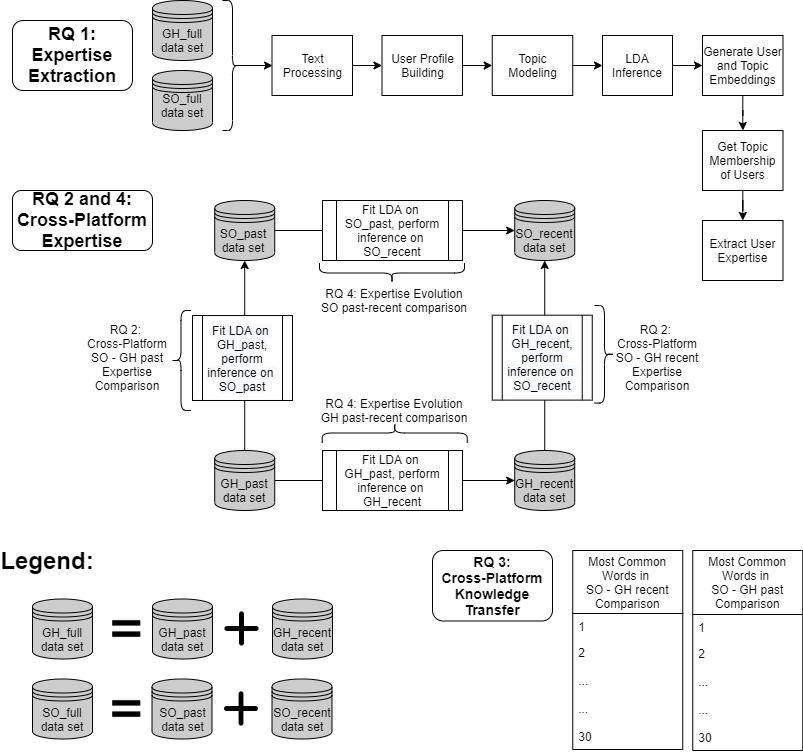
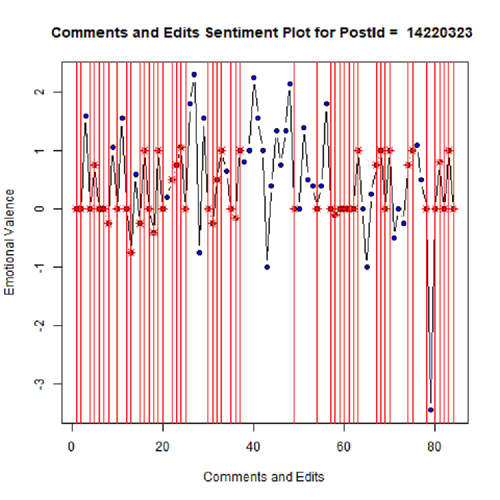
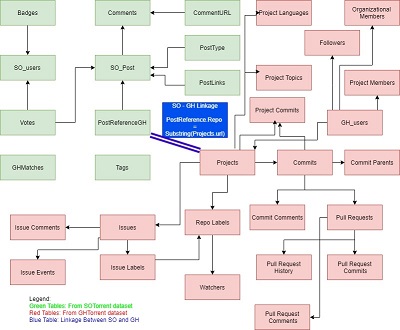
My Master’s thesis, entitled "Cross-Platform Software Developer Expertise Learning"
focuses on defining and quantifying the expertise of software developers based on publicly available data from GitHub and Stack Overflow.
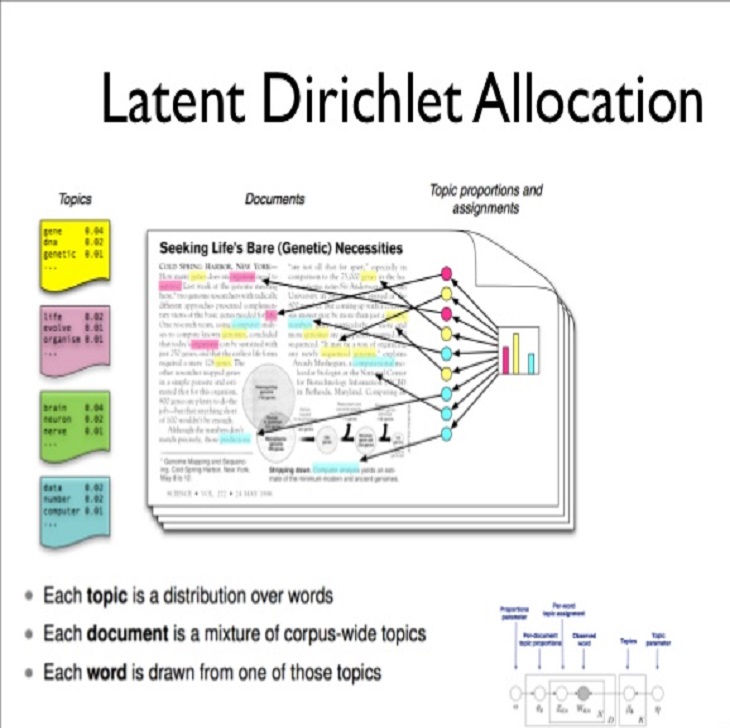
In order to achieve this goal, I worked with LDA topic models, which gave me an in-depth knowledge of Bayesian statistics.
My skill set includes (but not limited to):
- • Programming: PYTHON, R, SQL, JAVA, HTML, Javascript, Algorithm Design, Data Structures, Object Oriented Programming
- • Databases: Extensive experience with SQL, Database Design, BigQuery, MySQL, PostgreSQL, NoSQL
- • Software Engineering: Experienced with Client‑Server Applications (projects), Agile Development, Algorithm Implementation, CI & CD, Git, Deployment, Unit Testing, Writing Reports & Documentation
- • Cloud & Deployment: GCP (Vertex AI, App Engine, Compute Engine, Cloud Run, Cloud Build, Cloud Functions & Cloud Scheduler), Flask, Docker, Familiarity with Linux environments
- • ML & DS Libraries: TensorFlow, Keras, Scikit‑Learn, Scikit‑Optimize, Imbalanced‑Learn, PyCaret, StatsModels, Lifetimes, Tslearn, Sktime, Numpy, Pandas, Matplotlib, Plotly, Seaborn, Streamlit, SpaCy, Gensim, NLTK, dedupe, TextBlob
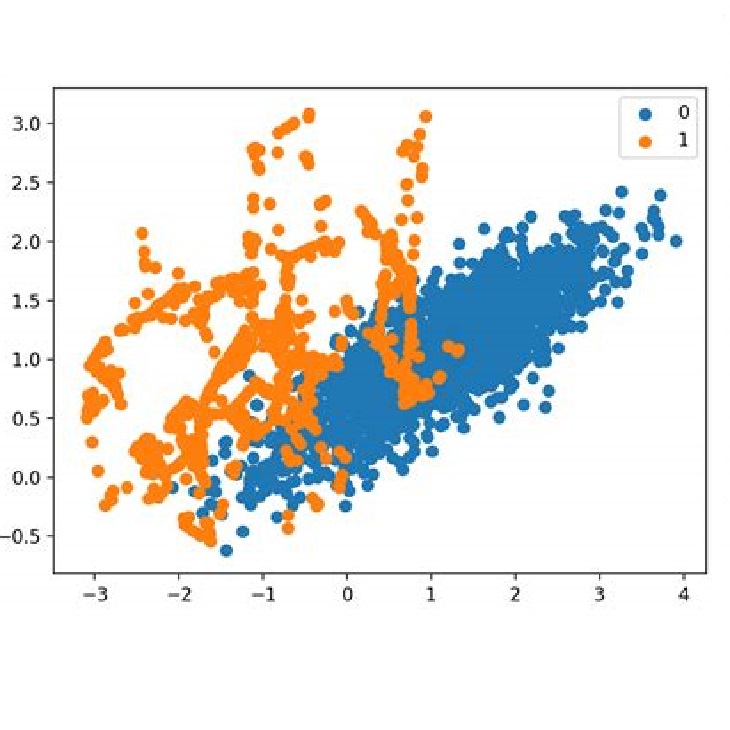
- • Machine Learning: Traditional ML (Random Forest, Decision Trees, SVM), Regression, Classification, Clustering, Time‑series Forecasting, Feature Selection, Outlier Detection, NLP, Hyper‑parameter Optimization
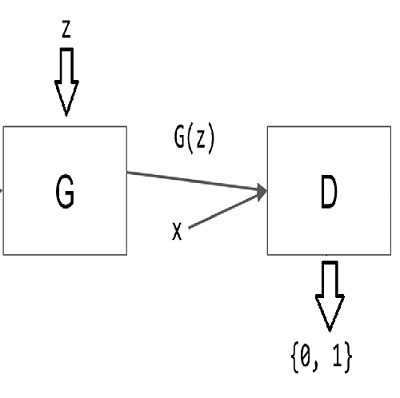
- • Deep Learning: Deep Neural Nets for NLP & Time‑series Forecasting using MLP, CNN, RNN, LSTM, GRU, GAN
- • Statistics: Descriptive Stats, Probability Theory, Regression Analysis, Bayesian Statistics, Statistical Modeling, Bayesian AB Testing, Inference, Dimensionality Reduction, Hypothesis Testing
- • Data Analysis: Extensive experience with Data Acquisition, Cleaning & Visualization (Streamlit & Looker dashboards), Feature Engineering, Data Mining, Predictive Modeling, Handling Unstructured Data
- • Interpersonal Skills: Teamwork, Intellectually Curious, Continuous Learner, Leadership & Communication Skills, Time Management, Self‑Starter, Motivated, Analytical Thinker, Data‑Driven Problem Solver
My interests include, but not limited to machine learning, healthcare applications of machine learning, financial data analysis, applications of deep learning, time series analysis & forecasting, outlier detection, classification tasks, cluster analysis, text analytics, data mining, sports analytics, real-time data analytics and simulations, motorsports data analytics & race strategy, conveying useful information through dashboard visualizations, and applications of computer vision and natural language processing.
Timeline.
 April 2023 - present:
I am starting a new position as Data Scientist at EF Education First in Zürich, Switzerland, where I will continue to grow my expertise in data science and machine learning.
July 2021 - April 2023:
I started a new position as Data Scientist at Migros Online, Switzerland’s largest digital supermarket, where I will continue to grow my skill set, transform raw data into actionable insights, and always strive to tell a story through data.
June 2021:
I relocated to Zürich, Switzerland to continue my professional journey here, in the heart of Europe.
February 2021 - June 2021:
I worked as a Data Scientist in Health Canada's Data Analytics and Reporting Team (DART) in the Regulatory Operations and Enforcement Branch in Ottawa, Canada.
June 19th, 2020:
Graduated with the Master of Computer Science Specialization in Data Science degree from Carleton University in Ottawa, Canada. See my LinkedIn post about it.
April 21st, 2020:
Successfully defended my Master's thesis titled Cross-Platform Software Developer Expertise Learning at Carleton University in Ottawa, Canada.
September 2018 - April 2020:
Graduate Research and Teaching Assistant at Carleton University
Master's thesis in mining Stack Overflow and GitHub creating a novel approach to cross platform software developer expertise learning
September 2019:
Featured in Carleton University's Eureka! magazine:
A LinkedIn post about my article can be found here.
This article was featured on Carleton University's Instagram and LinkedIn page as well
May 2019 - August 2019:
Data Scientist Intern at National Research Council Canada:
Worked in NRC's Data Analytics Center in Ottawa, and completed a 4 month contract for a government client
September 2018 - June 2020:
Carleton University - M.Sc. in Computer Science with Specialization in Data Science:
Data Mining, Machine Learning, NLP, Deep Learning and Empirical Software Engineering. Adviser: Prof. Olga Baysal
May 2017 - August 2017:
Undergraduate Researcher at University of British Columbia Okanagan:
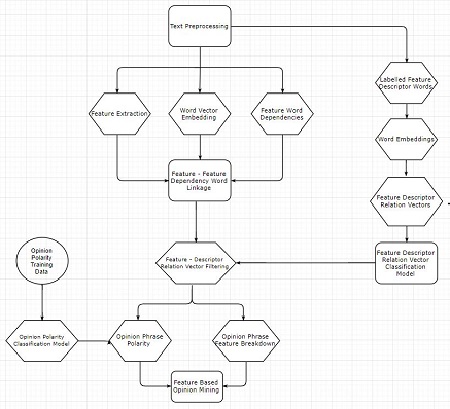
Received an Undergraduate Research Award and worked a modern approach to feature-based opinion mining, using word embeddings
September 2015 - April 2018:
Undergraduate Teaching Assistant at University of British Columbia Okanagan:
Helped students apply concepts taught in lectures via hands-on programming
September 2014 - June 2018:
University of British Columbia Okanagan - B.Sc. Honours in Computer Science, Minor In Data Science
Completed an Undergraduate Thesis Data Science project under the supervising of Prof. Abdallah Mohamed and Prof. Jeffrey Andrews
April 2023 - present:
I am starting a new position as Data Scientist at EF Education First in Zürich, Switzerland, where I will continue to grow my expertise in data science and machine learning.
July 2021 - April 2023:
I started a new position as Data Scientist at Migros Online, Switzerland’s largest digital supermarket, where I will continue to grow my skill set, transform raw data into actionable insights, and always strive to tell a story through data.
June 2021:
I relocated to Zürich, Switzerland to continue my professional journey here, in the heart of Europe.
February 2021 - June 2021:
I worked as a Data Scientist in Health Canada's Data Analytics and Reporting Team (DART) in the Regulatory Operations and Enforcement Branch in Ottawa, Canada.
June 19th, 2020:
Graduated with the Master of Computer Science Specialization in Data Science degree from Carleton University in Ottawa, Canada. See my LinkedIn post about it.
April 21st, 2020:
Successfully defended my Master's thesis titled Cross-Platform Software Developer Expertise Learning at Carleton University in Ottawa, Canada.
September 2018 - April 2020:
Graduate Research and Teaching Assistant at Carleton University
Master's thesis in mining Stack Overflow and GitHub creating a novel approach to cross platform software developer expertise learning
September 2019:
Featured in Carleton University's Eureka! magazine:
A LinkedIn post about my article can be found here.
This article was featured on Carleton University's Instagram and LinkedIn page as well
May 2019 - August 2019:
Data Scientist Intern at National Research Council Canada:
Worked in NRC's Data Analytics Center in Ottawa, and completed a 4 month contract for a government client
September 2018 - June 2020:
Carleton University - M.Sc. in Computer Science with Specialization in Data Science:
Data Mining, Machine Learning, NLP, Deep Learning and Empirical Software Engineering. Adviser: Prof. Olga Baysal
May 2017 - August 2017:
Undergraduate Researcher at University of British Columbia Okanagan:
Received an Undergraduate Research Award and worked a modern approach to feature-based opinion mining, using word embeddings
September 2015 - April 2018:
Undergraduate Teaching Assistant at University of British Columbia Okanagan:
Helped students apply concepts taught in lectures via hands-on programming
September 2014 - June 2018:
University of British Columbia Okanagan - B.Sc. Honours in Computer Science, Minor In Data Science
Completed an Undergraduate Thesis Data Science project under the supervising of Prof. Abdallah Mohamed and Prof. Jeffrey Andrews